




つづき。
はじめに
引き続き、雑学動画自動生成ツールを自作できないか、検討してみているお話です。
今回は、自然言語処理ライブラリである「GiNZA」について、雑学動画自動生成ツールで使えるか検証してみた話です。
検証準備
Pythonのインストール
「Python」で雑学動画自動生成ツールを作るつもりなので、検証でも同様に使います。
詳細は以下の記事にまとめていますので、ご興味ある方は、そちらをご覧ください。

PyCharmのインストール
Pythonでの開発を楽にしてくれる統合開発環境「PyCharm」を使います。
Pythonで雑学動画自動生成ツールを作る際に使うつもりなので、検証でも同様に使います。
詳細は以下の記事にまとめていますので、ご興味ある方は、そちらをご覧ください。

検証用Pythonプロジェクトおよびvenvの作成
検証用「Pythonプロジェクト」を作成します。
PyCharmで簡単に作成できます。
Pythonプロジェクトを作成したら、その中で「venv」(Python仮想環境)を作成しておきます。
詳細は以下の記事にまとめていますので、ご興味ある方は、そちらをご覧ください。


Pythonパッケージのインストール
今回は、以下のパッケージを使用します。
| No | パッケージ | 説明 |
|---|---|---|
| 1 | ja-ginza-electra | GiNZAにELECTRAという日本語用の事前学習モデルを組み合わせた高精度版です。 |
検証用Pythonプロジェクトでvenvを起動し、のパッケージをインストールします。
ターミナルでコマンド実行してインストールする方法やPyCharm上で画面を操作してインストールする方法がありますが、今回は、PyCharm上で画面を操作し、venvにパッケージをインストールします。

インストールする「GiNZA」のパッケージですが、PyCharm上で検索すると、「ginza」というキーワードが入ったパッケージがいくつか表示されました。
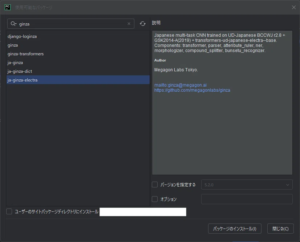
これらのパッケージについて少し調べたところ、以下のような結果となりました。
| No | パッケージ | 調査結果 | 採用可否 |
|---|---|---|---|
| 1 | django-loginza | ・GiNZAとは無関係なパッケージ | |
| 2 | ginza | ・古い ・ja-ginzaモデルを簡単に使えるようにするためのラッパー | |
| 3 | ginza-transformers | ・ja-ginza-electraで使用されているパッケージ | |
| 4 | ja-ginza | ・新しい ・標準モデル(メモリ消費は軽め、処理速度は速め) | ○ |
| 5 | ja-ginza-dict | ・ja-ginzaとja-ginza-electraで使用されているパッケージ | |
| 6 | ja-ginza-electra | ・新しい ・高精度モデル(メモリ消費が重め、処理速度は遅め) | ○ |
ということで、「ja-ginza」と「ja-ginza-electra」を選択して使えば良さそうです。
今回は、「ja-ginza-electra」をインストールして使います。
検証してみた
GiNZAを使用した日本語テキスト折り返し処理の流れ
以下の流れでGiNZAの日本語モデルを使っていくようでした。
- 「spaCy」を使いGiNZAの日本語モデルを読み込む
- 読み込んだ日本語モデルの言語オブジェクトを使い、日本語テキストを解析する
- 解析した結果を使い、文書や単語、句などを操作する
GiNZAを使用した日本語テキスト折り返し処理の試し
では実際に、GiNZAの日本語モデル「ja_ginza_electra」を使って、日本語テキストを折り返してみます。
GiNZAの日本語モデル「ja_ginza_electra」を使ったPythonサンプルコード
import spacy
# GiNZAの日本語モデルを読み込み
nlp = spacy.load("ja_ginza_electra")
def split_japanese_text(text, max_chars=20):
doc = nlp(text)
lines = []
current_line = ""
for token in doc:
# 句読点で一度改行を強制(自然な切れ目)
if token.text in "。!?":
current_line += token.text
lines.append(current_line.strip())
current_line = ""
continue
# 通常のトークン処理
if len(current_line + token.text) > max_chars:
lines.append(current_line.strip())
current_line = ""
current_line += token.text
if current_line:
lines.append(current_line.strip())
return "\n".join(lines)
# テスト
test_text = "私は昨日、友達と映画を見に行きました。そして今日は家でゆっくりしています。"
print(split_japanese_text(test_text, max_chars=10))Pythonサンプルコード実行結果
私は昨日、友達と映画
を見に行きました。
そして今日は家で
ゆっくりしています。ある程度、日本語テキストを自然に折り返せることが分かったので、雑学動画自動生成ツールで使えると感じました。
おわりに
「GiNZA」ですが、確かに日本語テキストを自然に折り返せることが分かりました。
サンプルコードでは、単純な日本語しか使っていないので、実際に雑学動画の日本語テキストで、どのような折り返しになるか確認していきたいです。
例えば、括弧が出た場合にどうするか、など、折り返しを見てから調整していきたいと思います。
これで、日本語テキストを折り返すために「GiNZA」を使えば良いことが分かったので、次の技術やツールの検証に移ろうと思います。
ちなみに、検証用のコードは、ChatGPT(GPT-4oモデル)に出力してもらったものを微修正したものです。
初めて使う技術の最小限のコードを簡単に確認できるので、便利だと思いました。
今回の記事も、同じように副業に悩んでいる人、手探りで取り組んでいる人にとって、何かの参考になれば嬉しいです。
これからも記録を続けていく予定なので、よければフォローしてもらえると嬉しいです。
つづき。


